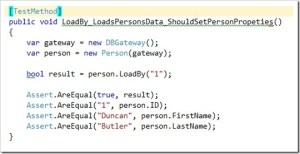
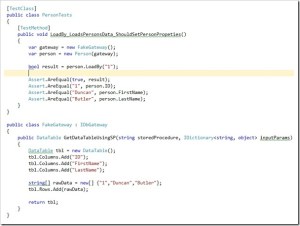
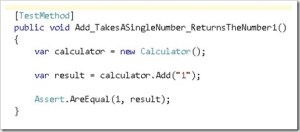
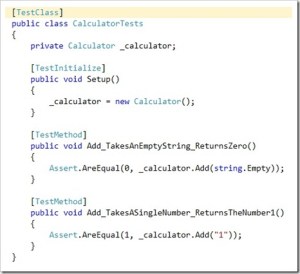
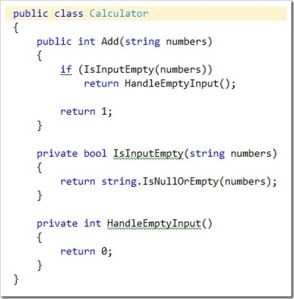
I have been using Spec Flow for the last few months as my feature specification framework, but sometimes the output I want to assert can be very repetitive, a simple example of this the string calculator kata.
Each part of the add feature specification is actually simply checking the return value given a specified input string.
using a traditional spec flow scenario specification it would look a bit like this
- Feature:Calculator Kata
- As a developer
- I want practice my craft
- So that I become a better developer
- Scenario: string calculator add method with input containing "1"
- Given the input stirng contains 1
- When add is called
- Then the result is 1
- Scenario: string calculator add method with input containing "1,2"
- Given the input stirng contains 1,2
- When add is called
- Then the result is 3
- Scenario: string calculator add method with input containing "1,2,3"
- Given the input stirng contains 1,2,3
- When add is called
- Then the result is 6
- etc……
lots of repeated code here, even using a regex to simplify the step definitions our feature file is going to get very long and difficult to maintain.
To help with just this sort of problem, Spec Flow supports the gherkin table construct this allows us to define the scenario steps separately from the data required by the steps, in this case our data is the input string “<input> and expected result <output>.
The steps are defined by a scenario outline with place holders for each of the required data values, and the data itself is defined in an examples table structure with a column for each place holder separated by the “|” pipe character.
- Scenario Outline: String calculator add method with valid input
- Given the input stirng contains ‘<input>’
- When add is called
- Then the result is ‘<output>’
- Examples:
- | input | output |
- | | 0 |
- | 1 | 1 |
- | 2 | 2 |
- | 1,2 | 3 |
- | 1,2,3 | 6 |
- | 1!2,3 | 6 |
- | //;!1;2 | 3 |
When the scenario is run it loops around replacing the place holders with each row of data, until either there is an error (fail) or it runs out of data (success).
The step definitions for the scenario outline are exactly the same as for a normal step definition, using a regex to extract the values passed by the framework, and handing them into the method definition as parameters.
- [Binding]
- public class CalculatorAddSteps
- {
- [Given(@"the input stirng contains ‘(.*)’")]
- public void GivenTheInputStirngContains(string inputString)
- {
- }
- [When(@"add is called")]
- public void WhenAddIsCalled()
- {
- }
- [Then(@"the result is ‘(.*)’")]
- public void ThenTheResultIs(int expected)
- {
- }
- }
Using the table structure is a very powerful way of displaying the data required by a specification, and controlling the number of scenarios that need to be written.